دیتا اینسایتز
در مورد علم داده، داده کاوی، هوشمندی کسب و کار(BI) و سایر مطالب مرتبطدیتا اینسایتز
در مورد علم داده، داده کاوی، هوشمندی کسب و کار(BI) و سایر مطالب مرتبطشناسایی موجودیت های اسمی فارسی
هفته گذشته زمان زیادی رو صرف این کردم که یک کتابخانه NER برای فارسی پیدا کنم. و خوب البته به خاطر محدودیت هایی که داشتم لازم بود که ترجیحا کتابخانه مورد نظر برای زبان JAVA هم API داشته باشه.متاسفانه کتابخانه آماده پیدا نکردم اما نتیجه جستجو به اینجا رسید که با استفاده از Stanford Core NLP و با استفاده از مجموعه داده تگ خورده PersianNER، خودم یک مدل ایجاد کردم. از آنجایی ساختن مدل حداقل 8 گیگ رم لازم داشت، تصمیم گرفتم فایل مدل به دست آمده را برای استفاده بقیه اینجا به اشتارک بگذارمش. فقط باید قبلش اشاره کنم که اولا طبق آنچه که تهیه کنندگان مجموعه داده PersianNER نوشته اند، این مجموعه فقط برای اهداف آکادمیک به اشتراک گذاشته شده و بنابراین در صورتی که قصد استفاده از این کتابخونه را دارید حتما به دو تا منبعی که توی پیج گیت هاب شون گفته اند ارجاع بدید. دوما اینکه مجموعه داده به صورت 3 بخش ( 3 fold) ارائه شده که مدلی که اینجا گذاشتم فقط توسط fold اول آموزش و تست شده.
و در پایان لینکهای زیر ممکنه به درد تون بخوره :
چطوری با استفاده از Stanford خودمون یک مدل NER آموزش بدیم؟
حذف کلمات توقف فارسی در R
در پکیج tm می توانید به سادگی با استفاده از دستور زیر کلمات توقف انگلیسی و چند زبان دیگر را از اسنادی که میخواهیم پردازش کنیم،حذف کنیم:
> docs <- tm_map(docs, removeWords, stopwords("english"))
برای اینکه لیست این کلمات را بینید کافیست دستور زیر را اجرا کنید :
>stopwords("english")
متاسفانه این پکیج لیستی از کلمات توقف فارسی ندارد و برای حذف کلمات فارسی کار کمی پیچیده تر است. اما نه خیلی !
برای این کار کافی است لیستی از کلمات توقف فارسی تهیه کنیم و آنها را داخل یک بردار بریزید و مثل بالا به تابع tm_map ارسالش کنید . برای اینکه کارتون تر تمیز و قابل استفاده مجدد باشد می توانید این کلمات را در یک فایل ذخبره کنید و هر بار که خواستید این کلمات را حذف کنید، آنها را از فایل مذکور بخوانید و به تابع tm_map ارسال کنید:
>stopwords <- readLines(stopwords_file_loc, encoding = "UTF-8")
>docs_swr <- tm_map(docs, removeWords, stopwords)
در کد بالا stopwords_file_loc آدرس فایلی است که کلمات مورد نظرتاان را در آن ذخیره کردید. به همین سادگی!
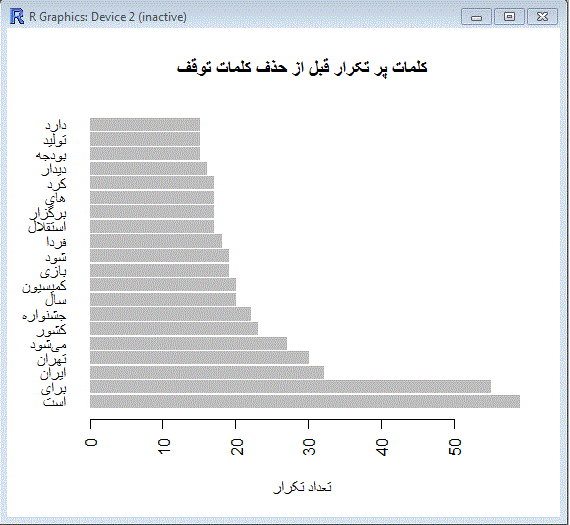
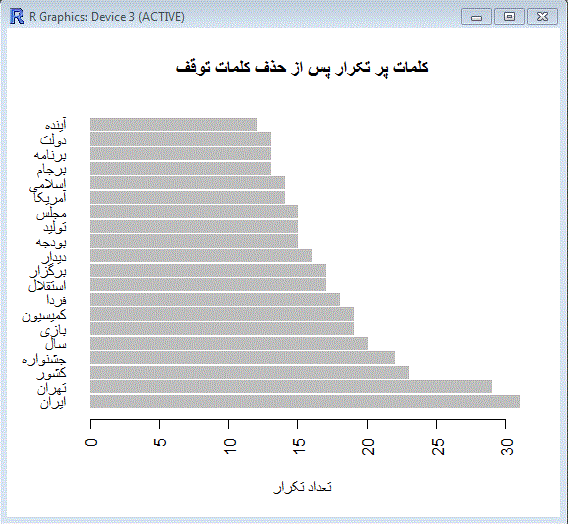
برای اینکه یک مثال عملی در اختیار داشته باشید. کد زیر را ببنید. توی این کد، اسناد را از یک فایل می خوانیم و یک بار بدون حذف کلمات توقف نمودار میله ای فرکانس کلمات پرتکرارش را رسم می کنیم و یکبار بعد از حذف کلمات توقف :
| نمونه کد |
| file_loc <- "C:\\rsamples\\documents.txt" stopwords_file_loc <- "C:\\rsamples\\stopwords.txt" files <- read.csv(file_loc, header = FALSE , encoding = "UTF-8") library (tm) docs <- Corpus(DataframeSource(files)) docs <-tm_map(docs,removePunctuation) docs <-tm_map(docs,stripWhitespace) docs <- tm_map(docs, PlainTextDocument) #-------- محاسبه ماتریس ترم-سند و رسم نمودار پرتکرارترین کلمات dtm <- DocumentTermMatrix(docs) m <- as.matrix(dtm) termFreq <- colSums(m) termFreq <-sort(termFreq , decreasing = TRUE) termFreq <- head(termFreq , 20) dev.new() barplot(termFreq , names.arg = names(termFreq) , horiz = T , las=2 , main="کلمات پر تکرار قبل از حذف کلمات توقف" , xlab="تعداد تکرار",border="gray" ) #--------حذف کلمات توقف و سپس محاسبه ماتریس ترم-سند و رسم نمودار پرتکرارترین کلمات stopwords <- readLines(stopwords_file_loc, encoding = "UTF-8") docs_swr <- tm_map(docs, removeWords, stopwords) dtm_swr <- DocumentTermMatrix(docs_swr) m_swr <- as.matrix(dtm_swr) termFreq_swr <- colSums(m_swr) termFreq_swr <-sort(termFreq_swr , decreasing = TRUE) termFreq_swr <- head(termFreq_swr , 20) dev.new() barplot(termFreq_swr , names.arg = names(termFreq_swr) , horiz = T , las=2 , main="کلمات پر تکرار پس از حذف کلمات توقف" , xlab="تعداد تکرار",border="gray" ) |
دو تا نمودار زیر هم خروجی های این قطعه کد هستند :
متن فارسی و R
یکی از سوالاتی که دوستان خیلی می پرسند نحوه خواندن متن فارسی در R و تعیین انکدینگ متن هست. خوب قطعا R و پکیجهای پردازش متن آن فقط برای زبان انگلیسی ساخته نشده. راه حل این مشکل این هست که موقع خواندن متن از فایلی که انکدینگ آن UTF-8 ( یا هر انکدینگ دیگه ای هست ) باید این را به R اعلام کنید. قطعه کد زیر متن فارسی زا از یک فایل به نام farsidocs.txt می خواند و بعد ابر کلمات آن را رسم می کند.
فرض بر این است که هر خط از فایل farsidocs.txt ، معادل یک سند است
|
| خولندن متن فارسی و رسم ابر کلمات آن با استفاده از R |
تاثیر حذف کلمات توقف
کلمات توقف، قبل از به کاربردن بسیاری از الگوریتم های متن کاوی، باید حذف شوند. این کلمات که بار معنایی خاصی ندارند، بسیاری از روشهای مبتنی بر آمار را به بیراهه می برند چرا که کاربرد خیلی زیادی در متن دارند بدون اینکه به موضوع یا مفهوم خاصی اشاره کنند. شکل های زیر ابر کلمات اخبار دیروز، 19 دی ماه 1394، را قبل و بعد از حذف کلمات توقف نمایش می دهد :
ابر کلمات قبل از حذف کلمات توقف

ابر کلمات پس از حذف کلمات توقف

تحلیل اتوماتیک اخبار هفته گذشته از 6دی (یکشنبه پیش) تا 12 دی (دیروز- شنبه)
تحلیل اتوماتیک اخبار هفته گذشته از 6دی (یکشنبه پیش) تا 12 دی (دیروز- شنبه)
فقط ابرکلمات و گراف باهم آیی کلمات را می گذارم. همین هم خوب نشان میدهد که هفته گذشته در دنیا چه خبر بوده است :


این هم لینک تیتر خبرهایی که استفاده کردم