دیتا اینسایتز
در مورد علم داده، داده کاوی، هوشمندی کسب و کار(BI) و سایر مطالب مرتبطدیتا اینسایتز
در مورد علم داده، داده کاوی، هوشمندی کسب و کار(BI) و سایر مطالب مرتبطبا توجه به اوضاع اگر خواستید فیلم ببینید از این لینک ها ببینید
https://dl2.sermoviedown.pw/
https://dls2.iran-gamecenter-host.com/DonyayeSerial
از API دیجیکالا تا یک دیتاست قابل استفاده
برای یکی از پروژههام به دیتای کاتالوگ یک فروشگاه آنلاین نیاز داشتم و اولین چیزی که به ذهنم رسید دیجیکالا بود.چند تا دیتاست از دیجیکالا روی Kaggle هست (مثلاً:
https://www.kaggle.com/search?q=digikala
)
ولی وقتی دقیقتر نگاه کردم دیدم هیچکدوم فیلدهایی که من لازم داشتم رو کامل ندارن.
برای همین تصمیم گرفتم خودم یه کرالر بنویسم. البته از صفر شروع نکردم و از این ریپو بهعنوان پایه استفاده کردم:
https://github.com/HB-2000/digikala_crawler
ولی چون APIهای دیجیکالا نسبت به قبل تغییر کرده بودن، عملاً مجبور شدم بخش زیادی از کد رو دوباره بنویسم و اصلاح کنم.
در نهایت کد نهایی پروژه و همینطور دیتایی که جمعآوری شده رو اینجا به اشتراک گذاشتم:
کد پروژه:
https://github.com/zahraEskandari/digikala_crawler
دیتای آماده (Release):
https://github.com/zahraEskandari/digikala_crawler/releases
اگه شما هم برای پروژههای دیتا، سرچ یا تحلیل به دیتای کاتالوگ دیجیکالا نیاز دارید، میتونید از این پروژه استفاده کنید یا بر اساس نیاز خودتون توسعهش بدید.
ماشین لرنینگ کلاسیک
با اینکه این روزها دیپلرنینگ و مدلهای زبانی بزرگ تقریباً همهجا موضوع بحث هستند،
اما واقعیت این است که مدلهای کلاسیک یادگیری ماشین هنوز هم در بسیاری از کاربردها نقش بسیار مهمی دارند. و همچنان استفاده خواهند شد چرا که در برخی صنایع مثل فینتک، صرفاً دقت بالاتر معیار تصمیمگیری نیست. حتی اگر مدلهای پیچیدهتر (مثل دیپلرنینگ) عملکرد عددی بهتری داشته باشند،نیازمندیهایی مثل:
قابلیت تفسیر تصمیمات مدل
شفافیت برای تیمهای بیزینسی و رگولاتوری
پایداری مدل در برابر تغییر توزیع دادهها
ریسک کمتر در استقرار و نگهداری
باعث میشود مدلهایی مثل Logistic Regression همچنان انتخاب اول باشند.
از طرف دیگر، سادگی این مدلها، نیاز کمتر به منابع محاسباتی و رفتار قابل پیشبینیشان در طول زمان،
دلایل مهم دیگری برای استفاده مداوم از آنهاست.
برای خود من، بارها پیش میآید که لازم است این مدلهای پایهای را دوباره مرور و یادآوری کنم.
به همین خاطر تصمیم گرفتم لینک ویدیوهایی را که با دیدنشان مفاهیم این مدلها برایم تازه میشود،
اینجا یکییکی جمعآوری کنم، هم برای خودم، هم شاید برای کسانی که مسیر مشابهی دارند.
Logistic Regression
ویدیو: https://www.youtube.com/watch?v=3bvM3NyMiE0
دانلود همین ویدیو: https://t.me/TechnicalNotesAI/2
این لیست به مرور کاملتر خواهد شد.,
یادگیری عمیق (Deep Learning) در یک آخرهفته
«دیپلرنینگ» همهجا هست. ولی منابع یادگیریش خیلی تئوریک و دانشگاهی هستند یا فقط API کال کردن یاد میدن و سطحی هستند. من اخیراً به یک ویدیوی آموزشی بلند و یکپارچه رسیدم که به نظرم برای مهندسها و دیتا ساینتیستها واقعاً ارزشمنده.
این دوره:
با PyTorch کار میکنه
از مفاهیم پایه (tensors, gradients) شروع میکنه
قدمبهقدم به آموزش شبکههای عصبی، آموزش مدل و حلقهی train میرسه
بدون شلوغکاری، بدون buzzword، با تمرکز روی «چرا و چطور»
و مهمتر از همه:
این یک ویدیوی تکهتکه نیست؛
بلکه یک آموزش چند ساعتهی پیوستهست که میتونه توی یک آخرهفته، تصویر ذهنی خیلی خوبی از Deep Learning بهتون بده.
لینک دوره:
https://www.youtube.com/watch?v=GIsg-ZUy0MY
من خودم برای استفادهی بهتر، ویدیو رو کامل دانلود کردم و فایلها و نوتبوکهای تمرینیش رو آماده کردم تا بشه همزمان با دیدن آموزش، کد زد و جلو رفت.
اگر شما هم:
دیتا ساینتیست هستین
مهندس نرمافزار یا بکاند
یا قبلاً ML کار کردین ولی DL براتون مبهم بوده
به نظرم این دوره یکی از بهترین نقطههای شروعه.
اگر فایلهای دوره و نوتبوکها رو میخواین، بهم ایمیل بزنید : technotesai@gmail.com
چطور برای مصاحبه در یک موقعیت شغلی به عنوان مهندس ماشین لرنینگ یا ML engineer آماده بشوم؟
مهندس ماشین لرنینگ، جزو شغلهایی ست که اخیرا در تمام دنیا و در ایران خیلی مورد نیاز است. افراد زیادی هم دنبال این هستند که با یادگیری اصول و مسائل بنیادی آن، کار خودشان را در این زمینه شروع کنند. پس هم موقعیت های کاری خوبی برای این زمینه کاری وجود دارد و هم افراد زیادی دنبال کسب این موقعیت ها هستند. ( بنابراین هم بین کارفرماها برای جذب نیروهای خوب و هم بین کارجو ها برای به دست آوردن موقعیت های بهتر رقابت خوبی وجود دارد!)
جالب این است که با وجود متقاضیان زیاد، متاسفانه در این رشته با کمبود نیروی متخصص و آماده به کار مواجه هستیم. اما چرا؟ نظر شخصی من با توجه به مصاحبه هایی که با کارجوهای این زمینه داشته ام این است که خیلی از افرادی که در بازار کار دنبال پوزیشن های کاری ماشین لرنینگ هستند، تنها آموزش یا تجربه ای که در این زمینه دارند گذراندن چند دوره آنلاین است. دوره های آنلاین از جمله دوره های ماشین لرنینگ در کورسرا و یودمی برای یادگرفتن و آشنایی با این رشته و مباحث آن، خیلی خوب هستند و افراد زیادی خود را مدیون آنها می دانند اما نکته ای که خیلی از کارجوها نادیده می گیرند این است که این دوره ها، مثل تمام دوره های آموزشی، برای تسهیل یادگیری و علاقه مند کردن افراد، ساده سازی شده اند. هدف این ساده سازی ها هم این است که سختی ها و پیچیدگی های اولیه موضوع و ابزارها دانشجو هایشان را دلسرد نکنند. اما متاسفانه، خیلی پیش می اید که کسانی که تجربه شان در ماشین لرنینگ به این دوره ها محدود می شود، تصور درستی از شرایط واقعی کار با داده ها ندارند و اغلب همان اطلاعاتی که از این دوره ها کسب کرده اند را برای شروع به کار کافی می دانند. بنابراین این پست را نوشتم تا تصور دقیق تری از مهارت ها و پیش نیازهای لازم برای شروع به کار در این زمینه به این افراد بدهم.
مهارت هایی که به نظر من برای کار در این رشته لازم دارید، اینها هستند :
مهارت های عمومی
دیسپلین داشتن، شناختن اهداف تسک هایی که به شما محول میشه و انجام تسک در راستای آن هدف ( goal oriented بودن)، اهمیت دادن و شناختن ارزشهایی که هر کدوم از تسک های شما برای کسب و کار فراهم می کند و اقدام بر اساس آنها ( business value کارها را حتما در نظر بگیرید.) . همزمان آرمانگرا و عملگرا باشید. بدانید که در هر شغلی ایجاد رابطه خوب و درست با همکاران تان در دراز مدت به اندازه درست انجام دادن تسک هایتان اهمیت دارد. علاوه بر این در موقعیت های شغلی که با داده ها مربوطند، مهارت های ارتباطی اهمیت ویژه ای دارند چون شما برای شناخت داده ها و فرآیندها معمولا لازم داریدکه با همکاران تان در بخش های مختلف شرکت صحبت کنید و ..
اینها را چطوری در خودمون تقویت کنیم؟ به آدمهای موفق نگاه کنیم، عادت های خوب و بدمان را بشناسیم و مطالعه کنیم، هر از چندی خودمون را ارزیابی کنیم و ...
یکی از دوستان سایت motamem.org را در بخش نظرات معرفی کردند. درسته. من خودم از بعضی مطالب این سایت استفاده کرده ام (ولی اگر باز اگر منبع مناسبی برای یادگیری و آشنایی با این مهارتها دارید، خوشحال می شوم که به من هم معرفی کنیدشان تا لینک آنها را اینجا با بقیه به اشتراک بگذارم.)
دانستن اصول و تعاریف اولیه و شناختن عمیق مدلها
اصول و تعاریف اولیه، چیزهایی هستند که ندانستن آنها موقعیت شما را توی مصاحبه خیلی تضعیف می کنه. از چیزهای ساده ای مثل تفاوت یادگیری با و بدون ناظر ،تفاوت test set و validation set، تعریف و تفاوت داده نویز و داده های پرت (outlier)
شناختن مدلهای معروف و پرکاربرد و دانستن اینکه هر کدوم از مدلها چه ویژگی هایی دارد؟ کجا و در برخورد با چه مسائلی باید از هر مدل استفاده کرد؟ سرعت آموزش هر یک از مدلها و سرعت پردازش هر مدل از نکاتی هستند که باید بدانید.به احتمال زیاد دوره ماشین لرنینگ Andrew Ng در کورسرا را دیده اید، من اینجا دوباره این دوره را توصیه می کنم. اما همانطور که گفتم نکته مهم دیدن دوره ها نیست، بلکه استفاده از آنها در پروژه های واقعی ست.
آمار و احتمالات
ریاضیات در ماشین لرنینگ خیلی مهم است. جبر خطی و آمار و احتمالات بلد باشید تا مدلهای ماشین لرنینگ را درک کنید. خصوصا آمار و احتمالات بلد باشید. وقتی با داده ها کار می کنید، ناچار باید به زبان آمار و احتمالات حرف بزنید. گذشته از این اغلب مدلهای ماشین لرنینگ آماری هستند. برای ارزیابی مدلها و همین طور پاکسازی داده ها و انتخاب فیچرها باید با مفاهیم ساده آماری مثل واریانس، میانگین، میانه و مفاهیم پیچیده تر مثل توزیع های آماری، فاصله اطمینان (Confidence Interval) و .. آشنا باشید.
اگر می خواهید جبرخطی و آمار و احتمال را با هدف استفاده از آنها در ماشین لرنینگ یاد بگیرید یا یادآوری کنید، دوره جبر خطی برای ML امپریال کالج لندن در کورسرا و و این پلی لیست را در کانال آکادمی خان در یوتوب را توصیه می کنم.
روشهای ارزیابی مدلها و مسائل مختلف/ ab test / test vs validation
حتما موقع مطالعه مدلها و روش های ماشین لرنینیگ با روشهای ارزیابی این مدلها هم آشنا شده اید و می دانید فرق validation set و test set چیست و accuracy، ق precision و recall چی هستند. اما خیلی از مدلها را نمی توان با روشهای معمول تست کرد. مثلا در پیاده سازی سیستم های پیشنهاد دهنده از A/B Testing برای مقایسه دو مدل مختلف استفاده می شود.
روشها و ابزارهای پاکسازی
کمتر پروژه ای وجود دارد که داده هایی که در اختیار شما قرار می گیرد نیاز به آماده سازی نداشته باشد , در این موقعیت شغلی بیش از 80 درصد زمان شما صرف پاکسازی و آماده سازی داده ها خواهد شد. بنابر این خیلی مهم است که انواع داده ها را بشناسید. روشها و ابزارهای پاکسازی مصور سازی آنها را بشناسید و بدانید با با داده های با شرایط خاص مثلا ابعاد زیاد یا کلاسهای نامتعادل چطور باید کار کنید. سعی کنید برای آمادگی بیشتر، مساله هایی با انواع داده مختلف را در سایت هایی مثل kaggle ببینید و حل کنید. و اگر جایگاه شغلی ای که قرار است در آن مشغول شوید یا به آن علاقه مند هستید روی داده هایی از نوع متن، تصویر و یا سیگنالهای صوتی متمرکز است شناختن روشهای پاکسازی خاص این نوع داده ها و چالشهایی که ممکن است با آن مواجه شوید حتما برای شما مزیت بزرگی خواهد بود.
یک نتیجه مستقیم پاراگراف بالا این است که انتظار نداشته باشید فقط مشغول کارهای خفن و آموزش مدلهای جدید روی داده ها باشید. در کار با داده ها باید صبور باشید چرا که اغلب مدلها بدون پاکسازی و آماده سازی داده ها نتایج مورد نظر شما را تولید نخواهند کرد!
بلد بودن یک زبان برنامه نویسی برای کار با داده ها
باید یک زبان برنامه نویسی را برای کار با داده ها خیلی خوب بلد باشیدبرای مثال پایتون. توجه کنید که برای اینکه در رزومه تان ادعا کنید پایتون بلد هستید لازم است اصول آن را خوب بشناسید و با آن کار کرده باشید. نوت بوک هایی که در دوره های درسی دیده اید و یا حتی کرنرهایی که در kaggle دیده اید برای اینکه ادعا کنید پایتون بلد هستید کافی نیست. این را برای این می گویم که گاها کارجویانی را دیده ام که در روزمه خود می نویسند تسلط بر پایتون اما عملا خودشان با آن کد ننوشته اند! علاوه بر اصول هر زبان لازم است تمیز کد نوشتن و تا حد امکان بهینه کد نوشتن با آن را هم بلد باشید و دنبال یادگرفتن best practice های آن زبان باشید. با ابزارهای version control مثل git، ابزارهای deploy و نگهداری از محصول آشنا باشید. و از آنجایی که قرار است با داده ها کار کنید باید کتابخانه های مربوط به داده و ماشین لرنینگ را خوب بشناسید. مثلا اگر به پایتون کد می زندید باید pandasو numpy، Scipy، SKlearn و .. را بشناسید،
اگر پایتون کد می زنید، برای استاندارد کد زدن مستندات PEP را دنبال کنید. برای اینکه بدانید چطور از virtual env یا docker در محیط پروداکشن استفاده می شود لینکهای زیر را ببینید :
https://towardsdatascience.com/managing-project-specific-environments-with-conda-b8b50aa8be0e
https://towardsdatascience.com/managing-project-specific-environments-with-conda-406365a539ab
https://medium.com/swlh/stop-using-anaconda-for-your-data-science-projects-1fc29821c6f6
برای یادگرفتن پایتون هم سایت ها و کتابهای زیر را ببینید :
و برای یادگرفتن git هم https://www.atlassian.com/git/tutorials را ببنید
فرایند انجام پروژه های ماشین لرنینگ
پروژه های ماشین لرنینگ هم مثل هر پروژه نرم افزاری دیگر در یک فرآیند انجام می شوند. و حتما شامل مراحلی مثل شناخت مساله، شناخت و درک داده ها و آماده سازی داده ها ، ساختن مدل و ارزیابی و آماده کردن آن برای استقرار خواهد بود. مهم است که این مراحل را بشناسید و پروژه ای که انجام می دهید، هر چقدر هم که کوچک باشد، تمام مراحل را طی کنید.
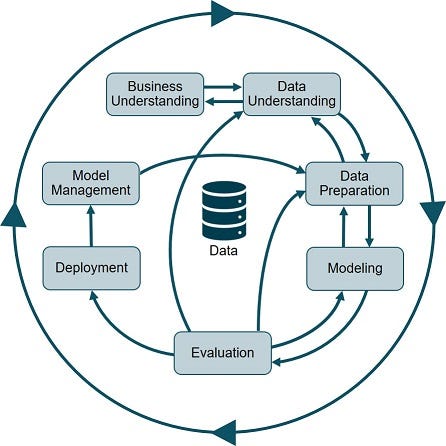
دنبال کردن سایت ها و آدمهای معروف این زمینه
سایت ها و آدمهای معروف این زمینه را دنبال کنید. kaggle و towardsdatascience , ... . خوشبختانه اکثر شرکتهای بزرگ و معروف وبلاگ فنی دارند و چالشهایی که با آنها مواجه می شوند و راه حلهایی که برای این چالشها استفاده می کنند را در وبلاگ شان به اشتراک می گذارند. می توانید یک لیست از وبلاگها و سایت هایی که من چک می کنم را در قسمت پیوندهای وبلاگ ببینید.
sql
شاید به اندازه کسانی که کارشان تحلیل دیتا ست نیاز به sql نداشته باشید. اما داده های مورد نیاز شما همیشه در یک فایل csv تمیز و آماده در اختیارتان قرار داده نمی شود و قطعا در حد خواندن داده ها و شاید حتی بررسی اولیه داده ها لازم است که بتوانید از دیتابیس های رابطه ای و حتی شاید NoSQL ها استفاده کنید. بنابراین آشنایی با زبان SQL از ملزومات کارتان خواهد بود. من حتی پا را فراتر می گذارم و معتقدم آشنایی با NoSQL ها هم برای شما لازم است. نه اینکه با تک تک دیتابیس های NoSQL کار کرده باشید. اما در مورد اینکه دیتابیس های NoSQL چه هستند، فلسفه به وجود آمدن شان چیست و چه انواعی دارند حتما برای شما مفید خواهد بود.
بیگ دیتا
آشنایی با فریم ورک های بیگ دیتا مثل Hadoop و Spark به خصوص در شرکتهایی که با حجم زیاد داده کار می کنند مزیت به حساب می آید. احتمالا از یک نیروی تازه کار انتظار تسلط بر این فریم ورک ها نمی رود. به خصوص که در ایران دسترسی به سرویس های ابری مثل Microsoft Asure ، AWS و ... ممکن نیست. اما آشنایی با کلیات می تواند مزیت به حساب بیاید.
برای مصاحبه آماده بشوید
با جستجوی عبارتی مثل "ml engineer interview questions" در گوگل می توانید با نوع سوالاتی که ممکن است در یک جلسه مصاحبه مواجه بشوید آشنا بشود. برای سوالات ساده مثل تعریف مفاهیم و یا توضیح نحوه عملکرد مدلهای مختلف تا سوالهای پیچیده آماده باشید. سخت ترین سوالات شاید آنهایی باشند که یک مساله از دنیای واقعی را مطرح می کنند و از شما می خواهند برای آن یک راه حل پیشنهاد دهید و بعد از شما می خواهند که توضیح دهید چرا این روش را برای پاکسازی داده انتخاب کردید یا چرا فلان مدل را استفاده کردید و نه بهمان مدل را و ...
در آخر چند تا نکته هست که لازمه به آنها اشاره کنم:
1 - از تعداد مهارتها و حجم چیزهایی که باید یاد بگیرید نترسید. لازم نیست برای شروع به کار در همه آنها عالی باشید.
2 - خیلی از مهارتهایی را که بالا لیست کردم را لازم است که حین کار و تجربه به دست بیاورید. اما آگاه بودن از آنها حتما به شما درحین مصاحبه و شروع کار کمک خواهد کرد.
3- هر روز خودتان را در حال آماده شدن برای مصاحبه بدانید و سعی کنید کارتان را با کیفیت انجام بدید. اگر مشغول به کار هستید یا در حین تجربه و انجام پروژه های درسی یا تمرینی، بدانید که در هر مصاحبه کاری، زمان زیادی در حال توضیح و تشریح کارهای فعلی تان هستید و کار فعلی شما ملاک ارزیابی شما خواهد بود.