دیتا اینسایتز
در مورد علم داده، داده کاوی، هوشمندی کسب و کار(BI) و سایر مطالب مرتبطدیتا اینسایتز
در مورد علم داده، داده کاوی، هوشمندی کسب و کار(BI) و سایر مطالب مرتبطحذف کلمات توقف فارسی در R
در پکیج tm می توانید به سادگی با استفاده از دستور زیر کلمات توقف انگلیسی و چند زبان دیگر را از اسنادی که میخواهیم پردازش کنیم،حذف کنیم:
> docs <- tm_map(docs, removeWords, stopwords("english"))
برای اینکه لیست این کلمات را بینید کافیست دستور زیر را اجرا کنید :
>stopwords("english")
متاسفانه این پکیج لیستی از کلمات توقف فارسی ندارد و برای حذف کلمات فارسی کار کمی پیچیده تر است. اما نه خیلی !
برای این کار کافی است لیستی از کلمات توقف فارسی تهیه کنیم و آنها را داخل یک بردار بریزید و مثل بالا به تابع tm_map ارسالش کنید . برای اینکه کارتون تر تمیز و قابل استفاده مجدد باشد می توانید این کلمات را در یک فایل ذخبره کنید و هر بار که خواستید این کلمات را حذف کنید، آنها را از فایل مذکور بخوانید و به تابع tm_map ارسال کنید:
>stopwords <- readLines(stopwords_file_loc, encoding = "UTF-8")
>docs_swr <- tm_map(docs, removeWords, stopwords)
در کد بالا stopwords_file_loc آدرس فایلی است که کلمات مورد نظرتاان را در آن ذخیره کردید. به همین سادگی!
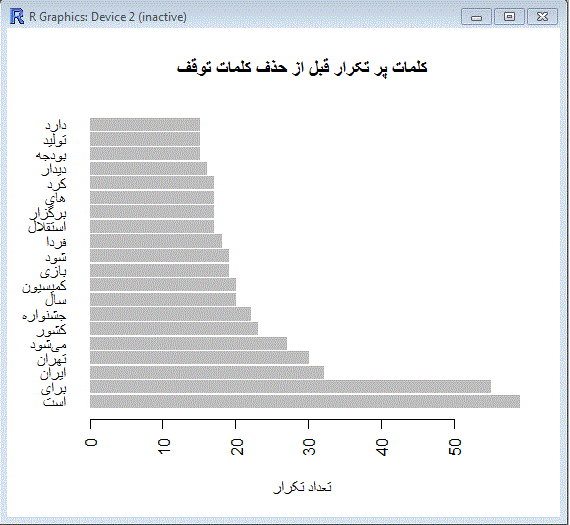
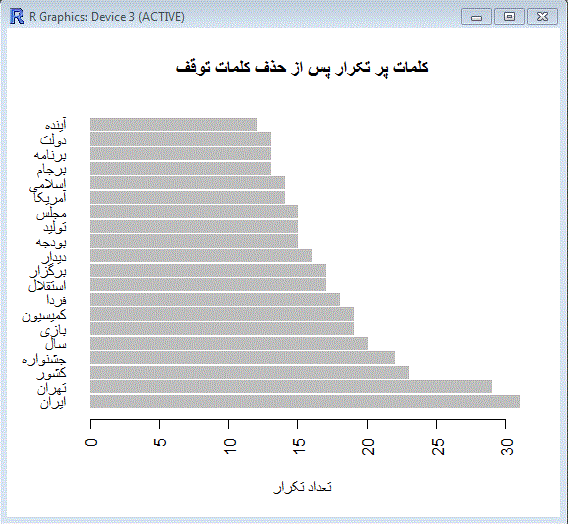
برای اینکه یک مثال عملی در اختیار داشته باشید. کد زیر را ببنید. توی این کد، اسناد را از یک فایل می خوانیم و یک بار بدون حذف کلمات توقف نمودار میله ای فرکانس کلمات پرتکرارش را رسم می کنیم و یکبار بعد از حذف کلمات توقف :
| نمونه کد |
| file_loc <- "C:\\rsamples\\documents.txt" stopwords_file_loc <- "C:\\rsamples\\stopwords.txt" files <- read.csv(file_loc, header = FALSE , encoding = "UTF-8") library (tm) docs <- Corpus(DataframeSource(files)) docs <-tm_map(docs,removePunctuation) docs <-tm_map(docs,stripWhitespace) docs <- tm_map(docs, PlainTextDocument) #-------- محاسبه ماتریس ترم-سند و رسم نمودار پرتکرارترین کلمات dtm <- DocumentTermMatrix(docs) m <- as.matrix(dtm) termFreq <- colSums(m) termFreq <-sort(termFreq , decreasing = TRUE) termFreq <- head(termFreq , 20) dev.new() barplot(termFreq , names.arg = names(termFreq) , horiz = T , las=2 , main="کلمات پر تکرار قبل از حذف کلمات توقف" , xlab="تعداد تکرار",border="gray" ) #--------حذف کلمات توقف و سپس محاسبه ماتریس ترم-سند و رسم نمودار پرتکرارترین کلمات stopwords <- readLines(stopwords_file_loc, encoding = "UTF-8") docs_swr <- tm_map(docs, removeWords, stopwords) dtm_swr <- DocumentTermMatrix(docs_swr) m_swr <- as.matrix(dtm_swr) termFreq_swr <- colSums(m_swr) termFreq_swr <-sort(termFreq_swr , decreasing = TRUE) termFreq_swr <- head(termFreq_swr , 20) dev.new() barplot(termFreq_swr , names.arg = names(termFreq_swr) , horiz = T , las=2 , main="کلمات پر تکرار پس از حذف کلمات توقف" , xlab="تعداد تکرار",border="gray" ) |
دو تا نمودار زیر هم خروجی های این قطعه کد هستند :